
Записки IT специалиста
Технический блог специалистов ООО»Интерфейс»
- Главная
- Оптимизация производительности PostgreSQL для работы с 1С:Предприятие
Оптимизация производительности PostgreSQL для работы с 1С:Предприятие
 PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
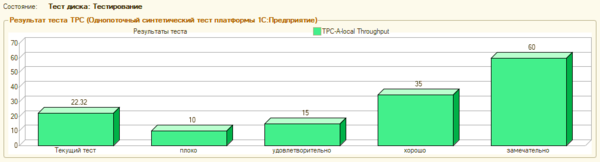 Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:\Program Files\PostgreSQL 1C\1х\data. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
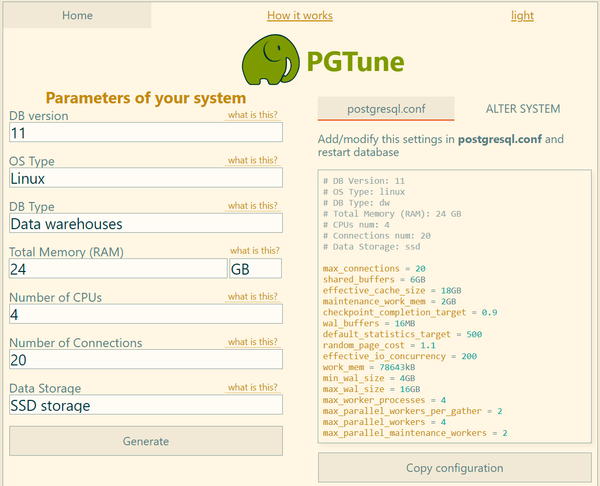 Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
Верхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
Допустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
Заставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
Альтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
Задает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
Минимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
Стоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
Определяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
Включение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
Время сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
Отключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
Данные опции специфичны для 1С и регулируют использование символа \ для экранирования.
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
В Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
 После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
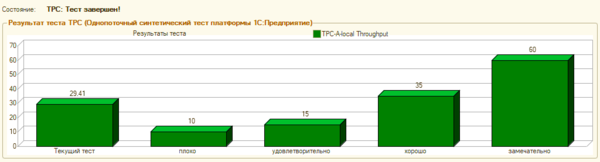 Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:

Или подпишись на наш Телеграм-канал: 
Прояснил для себя про Hyperthreading и 1с.
Из форума противоречивая инфа была.
HT OFF
Тест гилева файловый 8.3
http://snag.gy/bxyTC.jpg 60
Тест гилева серверный MSSQL2012 8.2.19.106
http://snag.gy/X5I1e.jpg 40
Тачка самосбор для извращений из купленного на ebay
xeon ES E5-2870 ($500)
память 1600 ecc kingston
супермикро 2 сокетовая
ssd samsung
Вобщем я так понял, что разницы принципиальной нет. А значит HT дб включен, тк нормальные приложения его любят и юзеров можно многа напустить.
(2) теплое с мягким перепутали.
во первых какая 1С?
7.7 вообще однопотоковая ей HT вредит, только частота нужна
8-ка а хз как там реализовано но скорее всего если нужна максимальная скорость для одного юзверя, то HT вредит.
если же нужна средняя температура по больнице то да многоядерность и HT врубайте )) не такие тормоза будут особенно когда какой нить антивирь или еще что решит проверить/обновиться ))
(11) Не стек, а контекст, я их часто путаю.
Блоки памяти копируются при общении клиентской части с SQL-сервером.
При переключении процесса регистры процессора пишутся в память (причём, также и регистры математического сопроцессора) — кеш, по идее, должен спасать.
Кстати, клиент-сервер на одной машине — это, как минимум, три процесса: SQL-сервер, сервер приложений и клиент. То, что они работают последовательно, обмениваясь данными, не мешает им быть разными процессами, так что в момент передачи данных от SQL-сервера через сервер приложений к клиенту может быть задействовано даже три ядра.
Другое дело, что в случае работы на одной машине SQL-сервер и сервер приложений обмениваются данными через «окно общей памяти». При этом, SQL-сервер готовит данные, потом все или по частям копирует их в «окно обмена», а сервер приложений в свою очередь копирует их из окна обмена в свою память.
Не забываем, что операции копирования выполняются через DMA (чаще всего) — в итоге, если запрос несложный, а данных много, то мы видит, что процессор просто простаивает, так как всё время тратится на процедуры копирования данных в памяти (их выполняет контроллер памяти и они всегда идут в один поток). Поэтому, на мощном сервере с хорошей дисковой подсистемой можно наблюдать, что программа не может загрузить даже одно ядро процессора.
(29)»ни предсказать ни ускорить ХТ ничего не может.»
Во первых HT ничего не должен предсказывать и ускорять по определению.
Во вторых именно в ситуации когда предсказать нельзя HT максимально эффективен. Он как раз работает в момент ошибок предсказания.
И еще, по поводу БД разве БД работает в вакууме? На сервере это единственный процесс? А как же система? Сторонние процессы тоже требуют процессорного времени, и делят его с БД.
Вот тут и помогает многопоточность вообще, и гипертрединг в частности.
(34) >Он как раз работает в момент ошибок предсказания.
Понимаешь как он работает? Он посылает на обработку следующую порцию данных, пока предыдущая переподготавливается. Да вот беда в случае баз данных следующая порция данных зависима от предыдущей и ее нельзя обработать пропустив первую.
Про отрисовку форм и прочую шваль и так понятно, но никакой пользы от многопоточности для базы данных нет, что и показывает практика.
(35)Опять ты за свое.
Вот представь — есть один процессор без гипертрединга, на нем работает БД, и «всякая шваль типа отрисовки окошек».
Итак проц занимается вычислениями для БД, и тут опа, ошибочка предсказания, усе, приехали, запрашиваем новые данные и нервно курим . дцать тактов пока они подгрузятся, ибо дело это не быстрое. Весь вычислительный конвеер процессора тупо простаивает.
В итоге 70% времени проц считает БД, 20% времени простаивает, и 10% времени считает всякую шваль.
Та же самая задача но процессор с гипертредингом.
После ошибки предсказания, переключается контекст, и вычислительный конвеер процессора просчитывает задачи для «всякой швали, типа отрисовки окошек»
В итоге 100% времени процессор считает БД, а всякая шваль успевает просчитаться во время простоев.
Это конечно в идеале в реальности все сложнее и есть накладные расходы, но они мизерные по сравнению с получаемым выигрышем в большинстве случаев.
Господа ну хватит бреда
Технология гиперпоточности
На технологии гиперпоточности стоит остановиться из-за того, как она влияет на SQL Server. Технология гиперпоточности фактически предоставляет операционной системе для одного физического процессора два логических процессора. По сути, технология гиперпоточности арендует время физических процессоров для полного использования возможностей каждого процессора. На веб-узле Intel (intel.com/technology/platform-technology/hyper-threading/index.htm) представлено гораздо более подробное описание работы технологии гиперпоточности.
В системах SQL Server DBMS фактически обрабатывает собственные чрезвычайно эффективные очереди и потоки для операционной системы, поэтому в системах с уже существующей высокой загрузкой процессоров технология гиперпоточности только еще больше перегружает физические ЦП. Когда SQL Server осуществляет постановку в очередь нескольких запросов для работы с несколькими планировщиками, операционной системе приходится переключать контекст потоков команд для обеспечения соответствия выполняемым запросам, даже если два логических процессора принадлежат одному физическому процессору. Если показатель «Контекстных переключений/сек» превышает 5000 для одного физического процессора, следует серьезно рассмотреть вопрос об отключении гиперпоточности в системе и повторном тестировании производительности.
Только в очень редких случаях приложения с высокой загрузкой процессора в SQL Server могут эффективно использовать гиперпоточность. Перед реализацией изменений в рабочих системах необходимо всегда проверять приложения в SQL Server с включенной и выключенной гиперпоточностью.
http://technet.microsoft.com/ru-ru/magazine/2007.10.sqlcpu.aspx
(41) это всего-лишь статья какого-то идиота Zach Nichter, и по сути своей — поебень, не цитируй этого говна больше.
HT это одна из технологий multi-threading, а конкретно раздача одного физического ядра на несколько потоков, коии есть и у Sun и у IMB, с другой реализацией, но одинаковым смыслом. Во время когда поток ожидает чего-то, ядро может заняться другим потоком, а не простаивать. При этом поток «ожидающий» с точки зрения ОС находится в состоянии running, иначе он был бы снял с процессора. Это уровень ниже приложения, которое только видит, что поток выполняется и всё, никакие очереди тут не помогут.
Даже если параллелить запросы не надо, в ОС всегда есть куча других потоков, которым нужен процессор.
Никакого смысла отключить HT нет, кроме разве что багов каких-то, когда приложение падает.
(49) у меня случай был когда драйвер модема валил сервак с гипертрейдингом 🙂
а вообще его следует рассматривать как виртуалку без отдельной памяти и другой перефирийки.
самые большие проблеммы для всех виртуалок это
1. приложение не видит реального железа и пытается что-то оптимизировать видя не реальную проблемму
2. конфликт блокировок к ресурсам
вторая проблемма возникает во всех многопоточных приложениях
первая проблемма возникает только в приложениях которые пытаются работать напрямую с железом. 1с сервер никогда не пытался работать напрямую с железом. про сервера БД — это отдельная песня.
(51) Если драйвер криво написан и ожидает данных от устройства, то даже небольшой «простой» при переходе к исполнению другого потока может приводить к тому, что данные будут получены кем-то другим или просто потеряны.
Если говорить, что гипертрейдинг мешает тем, что увеличивается число переключений, то есть подозрение, что до его включения система полностью перегружена.
Также не стоит забывать про «бутылочное горлышко» доступа к памяти — если память — слабое место, то добавление ядер (и даже полуядер) будет приводить только к снижению производительности, так как всё упрётся в обмен с памятью, а количество ядер просто добавит ещё операций с памятью при переключении потоков. Но, данный случай можно рассматривать как сильно перегруженный сервер.
Кстати, если у каждого ядра свой кеш, то накладные расходы на синхронизацию между потоками на различных ядрах требуют очистки кеша и обращения к памяти.
Ну и не забываем, что если программа считает, что ядер в два раза больше и создаёт количество потоков по количеству полуядер, то при оптимальной загрузке мы получаем, что два потока начинают конкурировать за одно ядро — в такой ситуации гипертрейдинг нужно отключать, так как можно будет наблюдать некоторое снижение производительности, однако, если программисты были умные, то они должны понимать, что потоков должно быть по числу обычных ядер, а не полуядер.
(55)ИМХО в том что касается 1с думаю тестировать нечего.
В результате все равно выяснится что в среднем HT в худшем случае не уменьшает быстродействия.
Вот во всяких узкоспециализированных областях, возможно незначительное ухудшение, но не в 1с.
(57) если на компе кроме 1С ничего нету то да быстродействие не уменьшится.
а если это не «сферический конь в ваккууме» а рабочая система со всякими антивирусами, скайпами и прочими оффисами то результат непредсказуем без тестов.



